The Problem
JM Die Company is a precision manufacturing company in the Chicago suburbs, supplying up to 15% of the cold-headed fastener tooling in the United States — the precision dies and punches behind the screws holding together everything from commercial aircraft to highway bridges. For years, every scanned blueprint, purchase order, packing slip, invoice, and shop floor document was captured via ScanSnap scanner and stored in Evernote. Twenty notebooks. Approximately 111,000 notes. Over 100 GB of data. The cost was roughly $300 per year.
Then Evernote's new ownership discontinued JM Die's plan and forced a migration to their Enterprise tier.
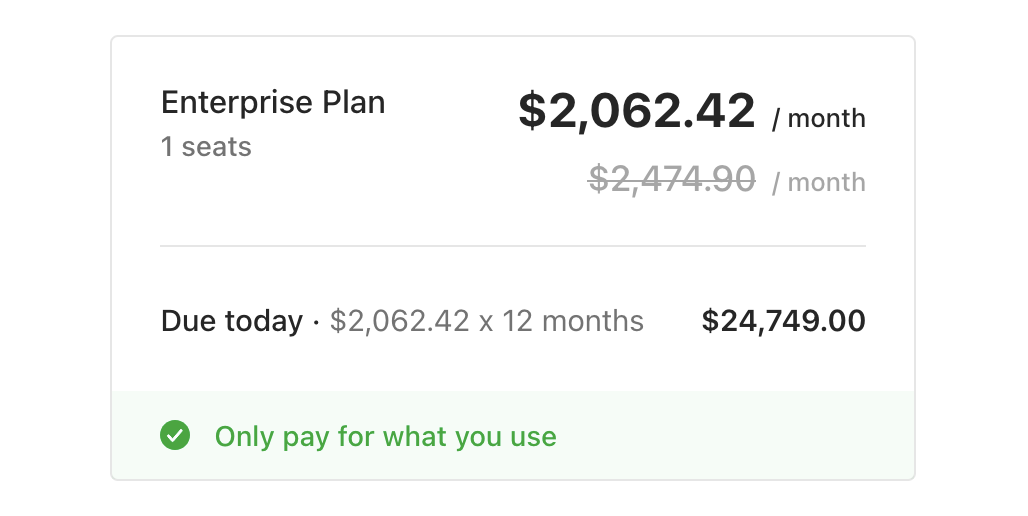
The actual checkout screen. $2,062.42/month for 1 seat.
An 80x price increase for the same single-user workload. The business wasn't going to pay ransom for its own data. But with 111K documents built up over years of daily operations, walking away meant a massive data migration — the kind most small manufacturers would simply pay to avoid.
The Decision
With 111,000 documents at stake, JM Die evaluated several migration paths: Notion, OneNote, Obsidian, Google Drive, and dedicated document management systems. The requirements were specific — the replacement needed to handle bulk .enex import at scale, provide full-text OCR search across the entire archive, and not impose per-seat enterprise pricing on what was fundamentally a single-user workflow.
Most alternatives failed on at least one count. Notion and OneNote choked on import volume. Traditional DMS platforms carried the same enterprise pricing problem JM Die was trying to escape. Google Drive offered storage but no document intelligence.
DocuStrata checked every box: browser-based Evernote import with progress tracking and resume capability, Tesseract OCR on every document at ingestion, full-text search across the entire corpus, and AI-powered document Q&A — all at $14/month. The migration ran overnight on a Mac with no IT involvement.
The Migration
The full Evernote library spanned 20 notebooks and over 100 GB of .enex export files — purchase orders, sales orders, scanned blueprints, packing slips, quotes, and general business documents accumulated over years. The largest single export was 35.9 GB containing over 21,000 notes.
| Scale | Value |
|---|---|
| Total notes | ~111,000 |
| Notebooks | 20 |
| Export volume | 102.5 GB |
| Largest single export | 35.9 GB |
A custom migration script was built to handle the scale. It streams each .enex file line-by-line — never loading more than one note into RAM — making it capable of processing files that are tens of gigabytes without breaking. Every document is OCR'd with Tesseract, deduplicated by MD5 hash, and uploaded to Supabase with full-text search indexing.
The system is fully resumable. A checkpoint file tracks progress every 10 notes, so overnight runs on 30+ GB files can be stopped and restarted without losing work. Evernote notebooks map directly to DocuStrata folders, with case-insensitive matching and automatic folder creation.
AI classification was intentionally deferred during the bulk import. Full-text search handles 90% of retrieval needs immediately. AI summaries can be backfilled later via batch API for the entire 111K document corpus — a fraction of a single month's proposed Evernote bill.
The Result
Full-Text Search
Every document searchable instantly. Part number lookups that used to require remembering which notebook something was filed in now search the entire 111K corpus in milliseconds.
AI Document Q&A
Open any document and ask questions in plain English. "What's the unit price on this PO?" or "Who's the vendor on this invoice?" — capabilities Evernote never offered at any price.
Manufacturing Integration
Documents forwarded via email are automatically tagged and surfaced in the company's manufacturing intelligence platform. Purchase orders, invoices, and packing slips flow directly into job tracking.
Scanner Workflow Replaced
The ScanSnap now saves directly to a watched folder. New scans are OCR'd and uploaded to DocuStrata automatically — no Evernote dependency in the workflow.
Lessons Learned
Streaming is non-negotiable at scale
Any migration tool that loads an .enex file into memory will fail on real-world datasets. The largest export here was 35.9 GB. Line-by-line streaming with backpressure is the only viable approach.
OCR first, AI later
The temptation is to run AI classification on every document during import. At scale, this multiplies cost and time by 10x with minimal immediate benefit. Full-text search covers 90% of retrieval needs. AI enrichment can be backfilled asynchronously.
Folder structure matters less than search
The 20 Evernote notebooks reflected how documents were captured — by scanner batch or document type — not how they're found. Users search by part number, customer name, or PO number. Not by browsing folders.
By the Numbers
| Metric | Value |
|---|---|
| Documents migrated | ~111,000 |
| Total data volume | 102.5 GB |
| Evernote notebooks | 20 |
| Migration throughput | ~1,400 notes/hour |
| Previous Evernote cost | ~$300/year |
| Proposed Evernote cost | $24,749/year |
| Current annual cost | $168/year |
| Savings vs. proposed plan | $24,581/year (99.3%) |
| Migration runtime | Multiple overnight runs |